Abstract
Volume rendering using neural fields has shown great promise in capturing and synthesizing novel views of 3D scenes. However, this type of approach requires querying the volume network at multiple points along each viewing ray in order to render an image, resulting in very slow rendering times. In this paper, we present a method that overcomes this limitation by learning a direct mapping from camera rays to locations along the ray that are most likely to influence the pixel’s final appearance. Using this approach we are able to render, train and fine-tune a volumetrically-rendered neural field model an order of magnitude faster than standard approaches. Unlike existing methods, our approach works with general volumes and can be trained end-to-end.
Background
While NeRF captures scenes at very high quality, a major limitation is that it takes a long time to train the model and render images. This is because the neural network representing the volume has to be queried along all the viewing rays. For an image of width \(w\), and height \(h\), and \(n\) depth samples, the rendering requires \(\Theta(nhw)\) network forward passes. With NeRF, it can take up to 30 seconds to render a \(800 \times 800\) image on a high-end GPU.
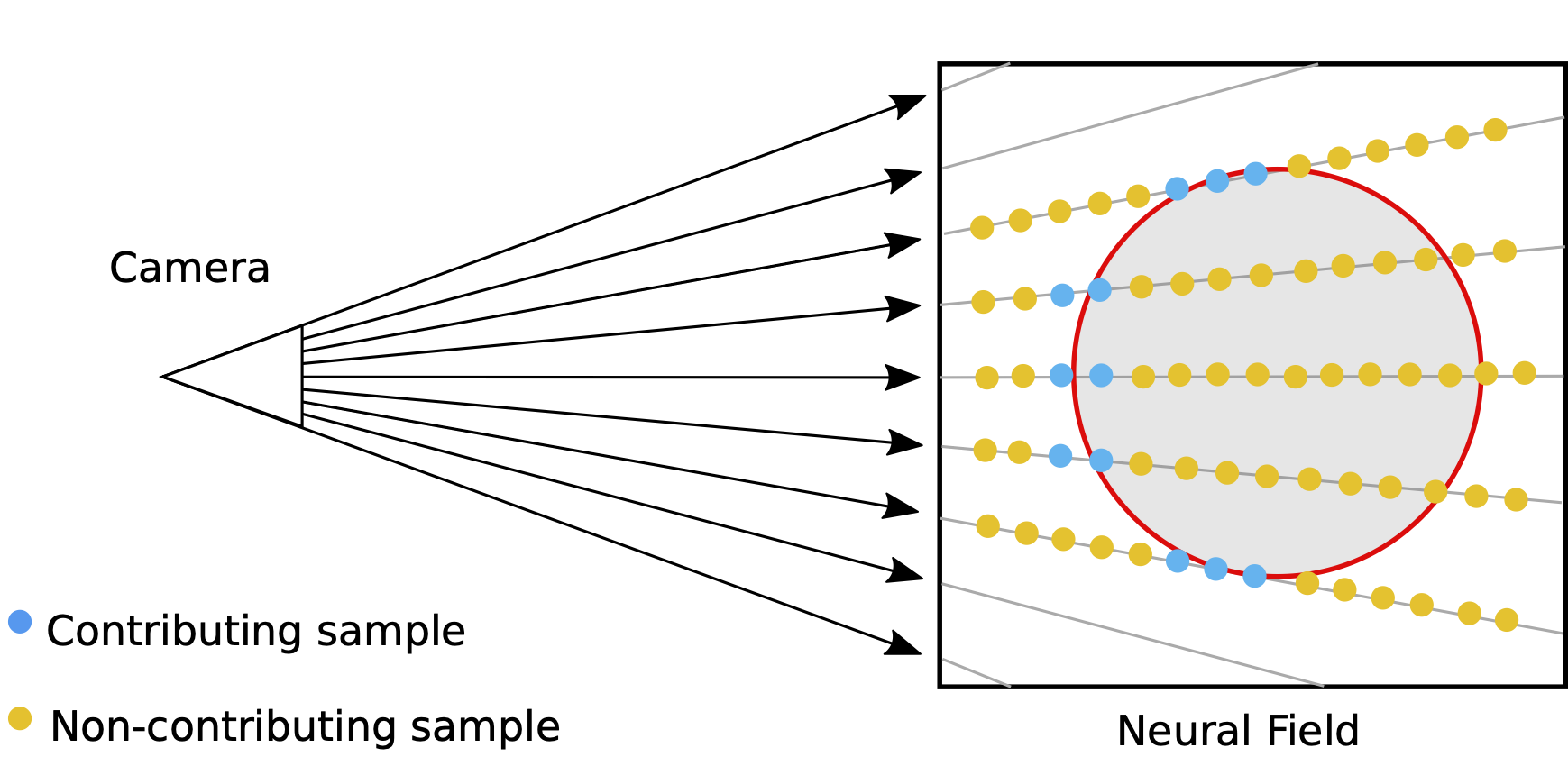
Of the many points sampled along each viewing ray, only a very small fraction contribute to the final color of the pixel. Our approach, called TermiNeRF, efficiently predicts the most important samples, speeding up the rendering \(\sim 14\) times.
Method
We propose a more efficient way to render (and train) a neural field model. Our approach works by jointly training a sampling network along with a color network, with the collective name TermiNeRF. The sampling network estimates where along the viewing direction the surfaces lie, thereby allowing the color network to be sampled much more efficiently, reducing the rendering time to less than 1s. This approach can be also applied to quickly edit a scene by rapidly learning changes to lighting or materials for a scene.

Rendering pipeline overview
To render an image, rays are first discretized into disjunct bins and each ray is then evaluated by the sampling network. The sampling network then determines the weight of each bin - the distribution of ideal sampling locations along the ray. Ray points drawn stochastically according to this distribution are then separately evaluated by the color network. The final color is aggregated via volumetric rendering.
Results
Rendering
A comparison of our method with the original NeRF implementation. For a fair comparison, images of both methods were produced with the same number of network forward passes per ray, 64 for the Radiometer, 32 for the rest. TermiNeRF 32 achieved the average \(7.32 \times\) speed-up in comparison with the original NeRF 64+128, whereas NeRF 8+16 renders the images \(7.99\times\) faster.
Fine-tuning and adaptation to a modified scene
In this experiment we adapt the network to a modified scene with similar geometry and different colors or lighting conditions. As the geometry stays the same as the original scene, we can reuse the already trained sampling network to guide the training of the color. This prior knowledge of the geometry allows us to speed up the training and adapt the network in a matter of minutes instead of hours.
Adaptation of the network to a modified scene and the corresponding training time required to adapt on a single Tesla T4 GPU.
Video Explanation
Conclusion
Neural Radiance Fields produce high-quality renders but are computationally expensive to render. In this paper, we propose a sampling network to focus only on the regions of a ray that yield a color, which effectively allows us to decrease the number of necessary forward passes through the network speeding up the rendering pipeline \(\approx 14 \times\).
The network performs one-shot ray-volume intersection distribution estimations, keeping the pipeline efficient and fast. We use only RGB data to train the model, which makes this method not only versatile, but also more accurate and suitable for translucent surfaces.